Using pre-trained context-specific deconvolution models
Source:vignettes/pretrainedModels.Rmd
pretrainedModels.RmddigitalDLSorteR offers the possibility to use
pre-trained context-specific deconvolution models included in the
digitalDLSorteRmodels R package (https://github.com/diegommcc/digitalDLSorteRmodels) to
deconvolute new bulk RNA-seq samples from the same biological
environment. This is the simplest way to use
digitalDLSorteR and only requires loading into R a raw
bulk RNA-seq matrix with genes as rows (annotated as SYMBOL)
and samples as columns, and selecting the desired model. This is done by
the deconvDDLSPretrained function, which normalizes the new
samples to counts per million (CPMs) by default, so this matrix must be
provided as raw counts. Afterwards, estimated cell composition of each
sample can be explored as a bar chart using the
barPlotCellTypes function.
Available models
So far, available models only cover two possible biological environments: breast cancer and colorectal cancer. These models are able to accurately deconvolute new samples from the same environment as they have been trained on.
Breast cancer models
There are two deconvolution models for breast cancer samples that differ in the level of specificity. Both have been trained using data from Chung et al. (2017) (GSE75688).
-
breast.chung.generic: it considers 13 cell types, four of them being the intrinsic molecular subtypes of breast cancer (ER+,HER2+,ER+/HER2+andTNBC) and the rest immune and stromal cells (Stromal,Monocyte,TCD4mem(memory CD4+ T cells),BGC(germinal center B cells),Bmem(memory B cells),DC(dendritic cells),Macrophage,TCD8(CD8+ T cells) andTCD4reg(regulatory CD4+ T cells)). -
breast.chung.generic: this model considers 7 cell types that are generic groups of the cell types considered by the specific version: B cells (Bcell), T CD4+ cells (TcellCD4), T CD8+ cells (TcellCD8), monocytes (Monocyte), dendritic cells (DCs), stromal cells (Stromal) and tumor cells (Tumor).
Colorectal cancer model
DDLS.colon.lee considers the following 22 cell types:
Anti-inflammatory_MFs (macrophages), B cells, CD4+ T cells, CD8+ T
cells, ECs (endothelial cells), ECs_tumor, Enterocytes, Epithelial
cells, Epithelial_cancer_cells, MFs_SPP1+, Mast cells, Myofibroblasts,
NK cells, Pericytes, Plasma_cells, Pro-inflammatory_MFs, Regulatory T
cells, Smooth muscle cells, Stromal cells, T follicular helper cells,
cDC (conventional dendritic cells), gamma delta T cells.
It has been generated using data from Lee, Hong, Etlioglu Cho et al., 2020 (GSE132465, GSE132257 and GSE144735). The genes selected to train the model were defined by obtaining the intersection between the scRNA-seq dataset and bulk RNA-seq data from the The Cancer Genome Atlas (TCGA) project (Koboldt et al. 2012; Ciriello et al. 2015) and using the digitalDLSorteR’s default parameters.
Example using colorectal samples from the TCGA project
The following code chunk shows an example using the
DDLS.colon.lee model and data from TCGA loaded from
digitalDLSorteRdata:
suppressMessages(library("digitalDLSorteR"))
# to load pre-trained models
if (!requireNamespace("digitalDLSorteRmodels", quietly = TRUE)) {
remotes::install_github("diegommcc/digitalDLSorteRmodels")
}## ── R CMD build ──────────────────────────────────────────────────────────────────────────────────────
##
checking for file ‘/private/var/folders/rp/4ctqf7314x3bz72jp9kyy06h0000gn/T/RtmpUBJ81j/remotes285e68d83089/diegommcc-digitalDLSorteRmodels-4d20300/DESCRIPTION’ ...
✔ checking for file ‘/private/var/folders/rp/4ctqf7314x3bz72jp9kyy06h0000gn/T/RtmpUBJ81j/remotes285e68d83089/diegommcc-digitalDLSorteRmodels-4d20300/DESCRIPTION’
##
─ preparing ‘digitalDLSorteRmodels’:
## checking DESCRIPTION meta-information ...
✔ checking DESCRIPTION meta-information
##
─ checking for LF line-endings in source and make files and shell scripts
##
─ checking for empty or unneeded directories
## ─ building ‘digitalDLSorteRmodels_1.0.0.tar.gz’
##
##
suppressMessages(library(digitalDLSorteRmodels))
# data for examples
if (!requireNamespace("digitalDLSorteRdata", quietly = TRUE)) {
remotes::install_github("diegommcc/digitalDLSorteRdata")
}
suppressMessages(library("digitalDLSorteRdata"))
suppressMessages(library("dplyr"))
suppressMessages(library("ggplot2"))Loading data
# loading model from digitalDLSorteRmodel and example data from digitalDLSorteRdata
data("DDLS.colon.lee")
data("TCGA.colon.se")DDLS.colon.lee is a DigitalDLSorterDNN
object containing the trained model as well as specific information
about it, such as cell types considered, number of epochs used during
training, etc.
DDLS.colon.lee## Trained model: 60 epochs
## Training metrics (last epoch):
## loss: 0.113
## accuracy: 0.6851
## mean_absolute_error: 0.0131
## categorical_accuracy: 0.6851
## Evaluation metrics on test data:
## loss: 0.0979
## accuracy: 0.7353
## mean_absolute_error: 0.0117
## categorical_accuracy: 0.7353
## Performance evaluation over each sample: MAE MSEHere you can check the cell types considered by the model:
cell.types(DDLS.colon.lee) %>% paste0(collapse = " / ")## [1] "Anti-inflammatory_MFs / B cells / CD4+ T cells / CD8+ T cells / ECs / ECs_tumor / Enterocytes / Epithelial cells / Epithelial_cancer_cells / MFs_SPP1+ / Mast cells / Myofibroblasts / NK cells / Pericytes / Plasma_cells / Pro-inflammatory_MFs / Regulatory T cells / Smooth muscle cells / Stromal cells / T follicular helper cells / cDC / gamma delta T cells"Now, we can use it to deconvolute TCGA.colon.se samples
as follows:
# deconvolution
deconvResults <- deconvDDLSPretrained(
data = TCGA.colon.se,
model = DDLS.colon.lee,
normalize = TRUE
)## === Filtering 57085 features in data that are not present in trained model## === Setting 0 features that are not present in trained model to zero## === Normalizing and scaling data## === Predicting cell types present in the provided samples##
1/17 [>.............................] - ETA: 0s
17/17 [==============================] - 0s 457us/step
##
17/17 [==============================] - 0s 466us/step## DONE## Anti-inflammatory_MFs B cells CD4+ T cells CD8+ T cells ECs ECs_tumor
## Sample_1 0.03555673 0.012629800 0.203374207 0.009651532 0.005541968 0.01741250
## Sample_2 0.04712306 0.066985361 0.074335054 0.037740961 0.034868978 0.04209921
## Sample_3 0.04327273 0.040529907 0.070434235 0.065242805 0.005649937 0.05630095
## Sample_4 0.06370531 0.087266162 0.000935028 0.025520567 0.063553512 0.06356230
## Sample_5 0.02191243 0.074413374 0.285449058 0.011043761 0.006262525 0.06074689
## Sample_6 0.05057833 0.009333167 0.053220294 0.045282345 0.007942556 0.05870201
## Enterocytes Epithelial cells Epithelial_cancer_cells MFs_SPP1+ Mast cells Myofibroblasts
## Sample_1 0.00930732 0.07155291 0.05909035 0.005882893 0.037573162 0.01825435
## Sample_2 0.04230683 0.03910230 0.02724862 0.064652219 0.043691453 0.06812529
## Sample_3 0.04989066 0.05444698 0.04421372 0.028884992 0.046738200 0.05523875
## Sample_4 0.04261205 0.01939960 0.06297676 0.021837080 0.006687696 0.02784961
## Sample_5 0.04846476 0.01496454 0.03080872 0.039284095 0.021862382 0.02031602
## Sample_6 0.01205215 0.15696418 0.00535871 0.020576831 0.106369674 0.02457043
## NK cells Pericytes Plasma_cells Pro-inflammatory_MFs Regulatory T cells
## Sample_1 0.20807561 0.04628119 0.03875881 0.004553903 0.0008091904
## Sample_2 0.07469992 0.02922466 0.01664687 0.024583310 0.0906273425
## Sample_3 0.05755381 0.02136340 0.04671244 0.007121265 0.0678701475
## Sample_4 0.06164910 0.04961384 0.03491505 0.019962540 0.0492653251
## Sample_5 0.04073286 0.02935412 0.02051809 0.061510801 0.1044049785
## Sample_6 0.03025280 0.01038808 0.04958447 0.001022621 0.1324385405
## Smooth muscle cells Stromal cells T follicular helper cells cDC gamma delta T cells
## Sample_1 0.004929547 0.02901828 0.100938693 0.034194998 0.04661205
## Sample_2 0.037988283 0.03085842 0.059172750 0.030084066 0.01783506
## Sample_3 0.036586583 0.08270273 0.036124319 0.065182000 0.01793948
## Sample_4 0.022256043 0.09293172 0.059893303 0.057660520 0.06594688
## Sample_5 0.024523739 0.04414549 0.004997781 0.006953675 0.02733000
## Sample_6 0.072353207 0.02527887 0.017107353 0.067269497 0.04335384deconvDDLSPretrained returns a data frame with samples
as rows
()
and cell types considered by the model as columns
().
Each entry corresponds to the proportion of cell type
in sample
.
To visually evaluate these results using a bar chart, you can use the
barplotCellTypes function as follows:
barPlotCellTypes(
deconvResults,
title = "Results of deconvolution of TCGA colon samples", rm.x.text = T
)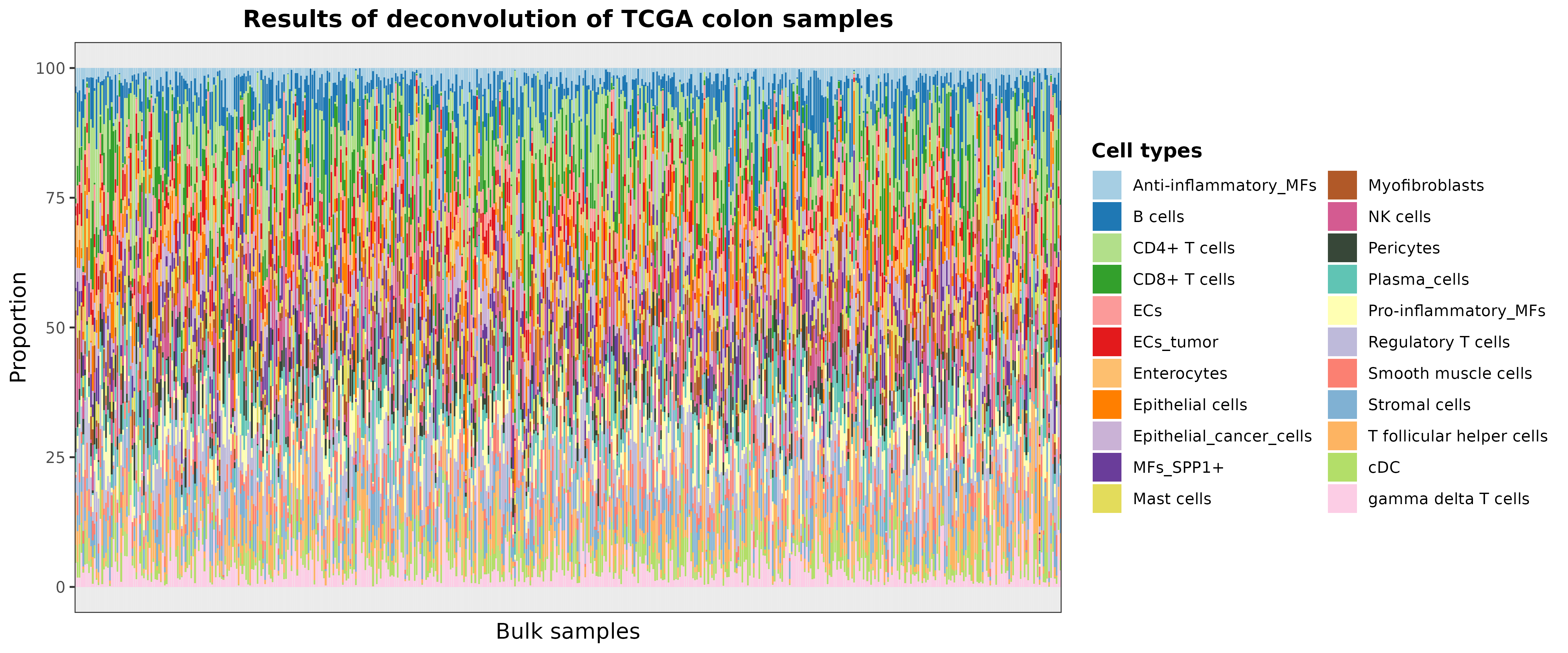
plot of chunk resultsDeconvTCGA_pretrainedModels
Let’s take 40 random samples just to improve the visualization:
set.seed(123)
barPlotCellTypes(
deconvResults[sample(1:nrow(deconvResults), size = 40), ],
title = "Results of deconvolution of TCGA colon samples", rm.x.text = T
)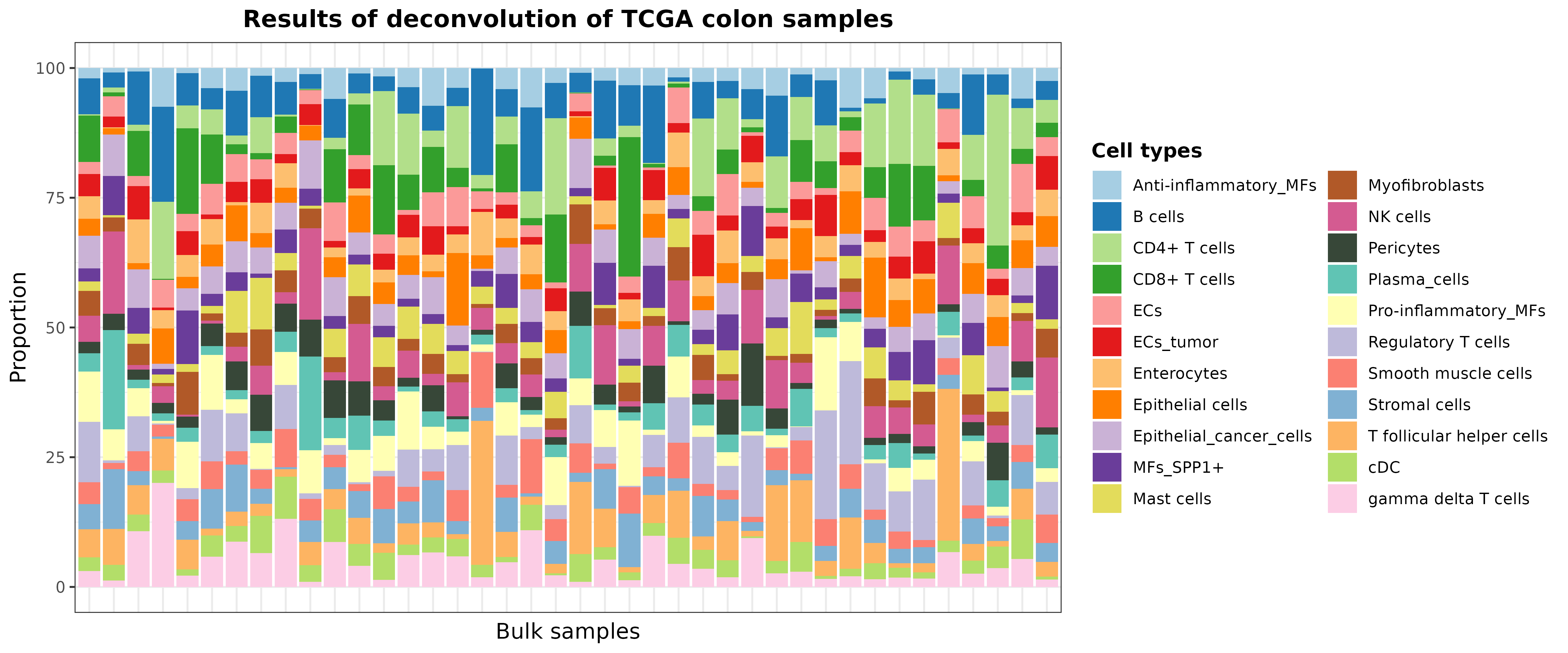
plot of chunk resultsDeconvTCGA_pretrainedModels_2
Finally, deconvDDLSPretrained also offers two parameters
in case you want to simplify the results by aggregating cell proportions
of similar cell types: simplify.set and
simplify.majority. For instance, we can summarize different
CD4+ T cell subtypes into a unique label by using the
simplify.set parameter as follows:
# deconvolution
deconvResultsSum <- deconvDDLSPretrained(
data = TCGA.colon.se,
model = DDLS.colon.lee,
normalize = TRUE,
simplify.set = list(
`CD4+ T cells` = c(
"CD4+ T cells",
"T follicular helper cells",
"gamma delta T cells",
"Regulatory T cells"
)
)
)## === Filtering 57085 features in data that are not present in trained model## === Setting 0 features that are not present in trained model to zero## === Normalizing and scaling data## === Predicting cell types present in the provided samples##
1/17 [>.............................] - ETA: 0s
17/17 [==============================] - 0s 433us/step
##
17/17 [==============================] - 0s 444us/step## DONE
rownames(deconvResultsSum) <- paste("Sample", seq(nrow(deconvResults)), sep = "_")
set.seed(123)
barPlotCellTypes(
deconvResultsSum[sample(1:nrow(deconvResultsSum), size = 40), ],
title = "Results of deconvolution of TCGA colon samples", rm.x.text = T
)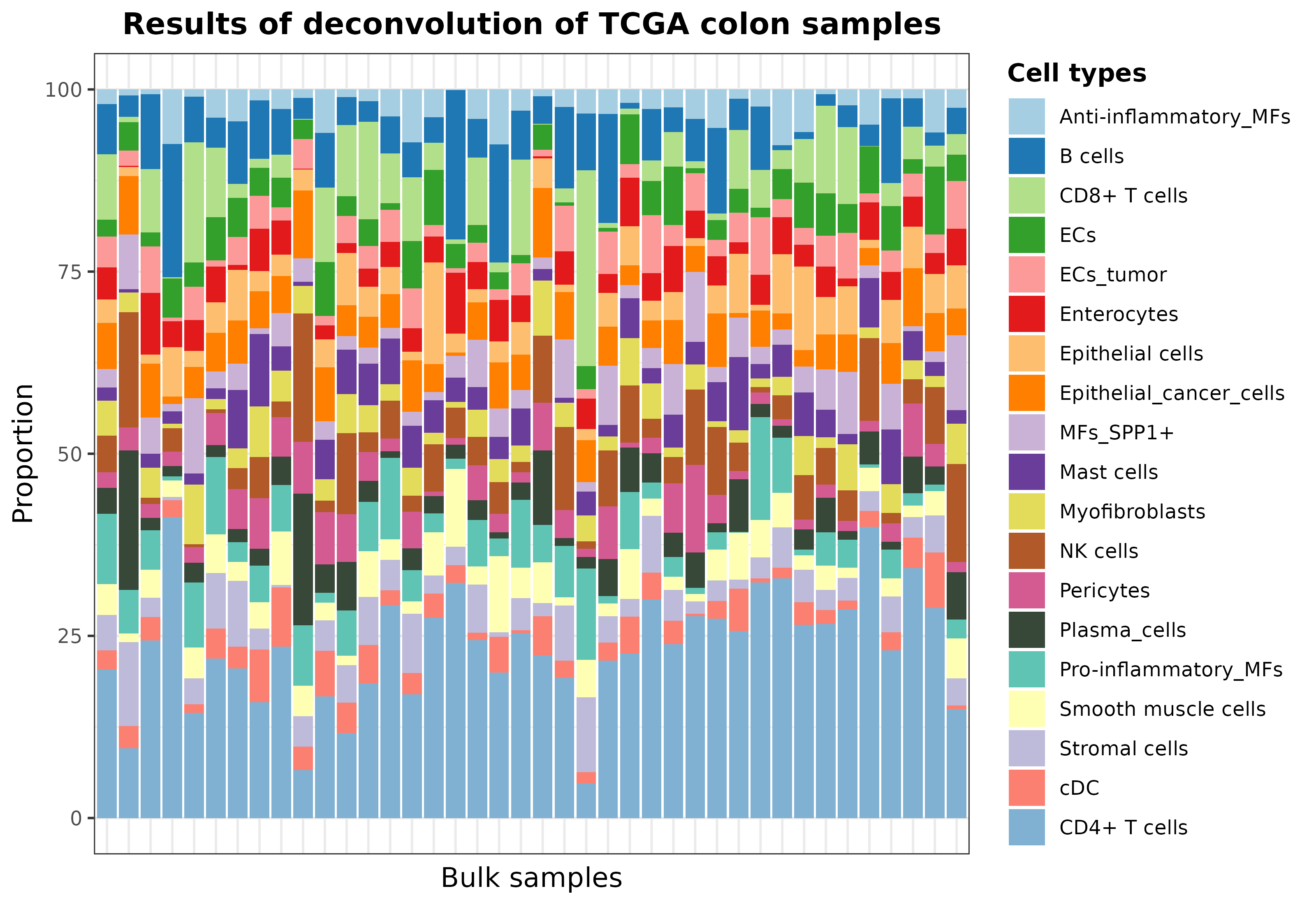
plot of chunk resultsDeconvTCGASimpl_pretrainedModels
On the other hand, simplify.majority does not create new
classes but sums the proportions to the most abundant cell type from
those provided in each sample. See the documentation for more
details.
Contribute with your own models
You can make available our own models to other users. Just drop an email and we will make them available at the digitalDLSorteRmodels R package!